Mit Windows Server 2012 (Enhanced in Windows Server 2012 R2) kam ein neues Feature; Data Deduplication. Dieses Feature ist aus meiner Sicht eines der besten Neuerungen der letzten Jahre, und gliedert sich nahtlos in Microsoft’s Storage Strategie ein. Data Deduplication ist ein Bordmittel, das kostenneutral dem Betriebssystem beigelegt wird. Die Liste wird immer länger; nicht nur die der Windows Storage Features, sondern auch die der Applikationen, die Daten auf SMB3 bzw. 3.02 ablegen können.
Obwohl auch mit Storage Spaces volle Redundanz gegeben ist, und ein Failover unter den richtigen Vorraussetzungen transparent erfolgt, muss man aber auch erwähnen, dass all diese Dinge massiv Performance beanspruchen können, und nicht jede Hardware dafür geeignet ist.
Fact ist aber, dass es gar nicht so lange her ist, als man für ein File Services Konzept eine recht einfache Liste erstellt hat, welche Gruppe mit welchem Recht auf die verschiedenen Shares Zugriff hat. Mit Server 2012 R2 muss die ganze Denkweise geändert werden. Angefangen an der Hardware über virtuelle Storage Spaces bis hin zu einem horizontal skalierbaren Fileserver.
Aber zurück zum eigentlichen Thema; nach der Installation der Data Deduplication werden wir uns anschauen, was unter der Haube passiert.
Installation
Das Installieren und Einschalten der Data Deduplication ist nicht sonderlich aufwendig; innerhalb der File Services Role die Option Data Deduplication auswählen und installieren oder wie folgt per Powershell
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
PS C:\Users\administrator.PLAYGROUND> Get-WindowsFeature -name FS*
Display Name Name Install State
------------ ---- -------------
[X] File Server FS-FileServer Installed
[ ] BranchCache for Network Files FS-BranchCache Available
[ ] Data Deduplication FS-Data-Deduplication Available
[ ] DFS Namespaces FS-DFS-Namespace Available
[ ] DFS Replication FS-DFS-Replication Available
[X] File Server Resource Manager FS-Resource-Manager Installed
[ ] File Server VSS Agent Service FS-VSS-Agent Available
[ ] iSCSI Target Server FS-iSCSITarget-Server Available
[ ] Server for NFS FS-NFS-Service Available
[ ] Work Folders FS-SyncShareService Available
[X] SMB 1.0/CIFS File Sharing Support FS-SMB1 Installed
[ ] SMB Bandwidth Limit FS-SMBBW Available
PS C:\Users\administrator.PLAYGROUND> Add-WindowsFeature -name FS-Data-Deduplication
Success Restart Needed Exit Code Feature Result
------- -------------- --------- --------------
True No Success {Data Deduplication}
WARNING: Windows automatic updating is not enabled. To ensure that your newly-installed role or feature is
automatically updated, turn on Windows Update.
PS C:\Users\administrator.PLAYGROUND> Get-WindowsFeature -name FS*
Display Name Name Install State
------------ ---- -------------
[X] File Server FS-FileServer Installed
[ ] BranchCache for Network Files FS-BranchCache Available
[X] Data Deduplication FS-Data-Deduplication Installed
[ ] DFS Namespaces FS-DFS-Namespace Available
[ ] DFS Replication FS-DFS-Replication Available
[X] File Server Resource Manager FS-Resource-Manager Installed
[ ] File Server VSS Agent Service FS-VSS-Agent Available
[ ] iSCSI Target Server FS-iSCSITarget-Server Available
[ ] Server for NFS FS-NFS-Service Available
[ ] Work Folders FS-SyncShareService Available
[X] SMB 1.0/CIFS File Sharing Support FS-SMB1 Installed
[ ] SMB Bandwidth Limit FS-SMBBW Available
|
Konfiguration
Dedup wird für Partition H: aktiviert,
|
1
2
3
4
5
6
7
|
PS C:\Users\administrator.PLAYGROUND> Enable-DedupVolume h:
Enabled UsageType SavedSpace SavingsRate Volume
------- --------- ---------- ----------- ------
True Default 0 B 0 % H:
|
wenn man ein Hyper-V Storage Volume benötigt gibt man die Option ‚-UsageType HyperV‘ an, by default hat man einen ‚General Purpose File Server‘ mit einer Deduplizierung von Daten älter als 3 Tage
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
PS C:\Users\administrator.PLAYGROUND> Get-DedupVolume | fl -Property *
ObjectId : \\?\Volume{63bde5fa-01c9-4834-9061-69b19d3856ea}\
UsageType : Default
Capacity : 21338517504
ChunkRedundancyThreshold : 100
DataAccessEnabled : True
Enabled : True
ExcludeFileType :
ExcludeFileTypeDefault : {edb, jrs}
ExcludeFolder :
FreeSpace : 20661751808
MinimumFileAgeDays : 3
MinimumFileSize : 32768
NoCompress : False
NoCompressionFileType : {asf, mov, wma, wmv...}
OptimizeInUseFiles : False
OptimizePartialFiles : False
SavedSpace : 0
SavingsRate : 0
UnoptimizedSize : 676765696
UsedSpace : 676765696
Verify : False
Volume : H:
VolumeId : \\?\Volume{63bde5fa-01c9-4834-9061-69b19d3856ea}\
PSComputerName :
CimClass : ROOT/Microsoft/Windows/Deduplication:MSFT_DedupVolume
CimInstanceProperties : {Capacity, ChunkRedundancyThreshold, DataAccessEnabled, Enabled...}
CimSystemProperties : Microsoft.Management.Infrastructure.CimSystemProperties
|
Für das Testsystem werden die MinimumFileAgeDays genullt, damit alle Daten dedupliziert werden. Für ein Produktiv System macht das nullen Sinn, wenn Daten längerfristig liegen bleiben; damit sich die aufgewandte Performance rentiert hat!
|
1
2
3
|
Set-DedupVolume -Volume H: -MinimumFileAgeDays 0
|
Dedupe Config
Nach dem Einschalten der Dedupe Option gibt es auf der entsprechenden Partition einen neuen Ordner im Hidden ‚System Volume Information‘ Ordner mit dem Namen ‚Dedup‘

Die Config sowie verschiedene Statusinformationen liegen auf dem Volume. Es ist sozusagen eine ‚in a box‘ Lösung. Das hat den Vorteil, dass nach einem Restore oder Einhängen der Partition auf neuer Hardware oder OS, Config und Daten beisammen sind.
trigger an Optimization
|
1
2
3
4
5
6
7
8
9
|
PS C:\Users\administrator.PLAYGROUND> Start-DedupJob H: -Type Optimization -Memory 50
PS C:\Users\administrator.PLAYGROUND> Get-DedupStatus -Volume H:
FreeSpace SavedSpace OptimizedFiles InPolicyFiles Volume
--------- ---------- -------------- ------------- ------
19.02 GB 449.13 MB 44 44 H:
|
Der erste Optimization Job ist manuell gelaufen und hat das oben gezeigte Ergebniss erzielt.
Da Dedupe noch nicht on the fly geschieht muss dies automatisiert werden. Mit folgendem Powershell Befehl lassen wir uns den Zeitplan anzeigen:
|
1
2
3
4
5
6
7
8
9
|
PS C:\Users\administrator.PLAYGROUND> Get-DedupSchedule
Enabled Type StartTime Days Name
------- ---- --------- ---- ----
True Optimization BackgroundOptimization
True GarbageCollection 02:45 Saturday WeeklyGarbageCollection
True Scrubbing 03:45 Saturday WeeklyScrubbing
|
wie man sieht, gibt es 3 Jobs, den eigentlichen Optimization, den wir eben manuell angetriggered haben sowie eine Garbage Collection und Scrubbing.
Die Optimization scheint keinen Zeitplan zu haben, steht aber auf True. Tasks werden über den Task Scheduler getriggered. Unter dem Ordner Microsoft/Windows/Deduplication findet man diese 3 Tasks, die Namen weichen minimal ab! Die BachgroundOptimization wird täglich um 1:45 gestartet und hat einen repeat every hour. Der Job läuft also einmal stündlich. Die anderen beiden einmal die Woche.
Wer die Disk in einen Failover Cluster eingebunden hat wird diese Jobs im Ordner Microsoft/Windows/Failover Clustering finden.
Background Optimization
der Standard Background Optimization job läuft gemütlich im Hintergrund, mit einer maximalen RAM allocation von 25%. Dazu lässt sich noch der Throughput Optimization job einschalten, der für Leerlaufzeiten gedacht ist, da er sich im Gegensatz zum default job nicht drosseln lässt, mit Priority Normal und 50% RAM läuft.
Der Job optimiert das Laufwerk, indem es auf die Richtlinie zutreffende Files dedupliziert und Chunks (Dateiblöcke) komprimiert.
Garbage Collection
Die Garbage Collection ist vielleicht bekannt aus anderen Deduplizierungs Lösungen wie z.B. Data Domain oder Avamar. Im Grunde wird ein Chunk, wie auch ein File beim Löschen nicht wirklich gelöscht. Ein File wird als löschbar markiert und bei Bedarf überschrieben. Auf einen Chunk allerdings wird mehrfach referenziert. Die Garbage Collection prüft die Referenzen des Chunks und entfernt diesen, wenn er nicht mehr gebraucht wird. Dieser Vorgang ist sehr Performance intensiv. Bei grösseren File Servern sollte die Garbage Collection gemonitored und der Zeitplan evtl. angepasst werden.
Data Scrubbing
Data Scrubbing ist ein Datenintegritätsfeature zum Überprüfen der Metadaten auf Konsistenz und Validierung von Prüfsummen. Durch das Arbeiten und Umschlichten der Chunks, können Corruptions auftreten, die dann in einem Logfile festgehalten werden. Das Scrubbing analysiert das Logfile, und versucht beschädigte Chunks zu restoren.
Aber woher bekommt man den Chunk zurück, wenn er nicht mehr reparabel ist? Man bedenke, das die Deduplizierung ja alle Chunks löscht, die doppelt vorherschen!
Folgende Möglichkeiten: Falls der Storage Space via OS gespiegelt ist, lässt sich evtl. ein intakter Chunk vom Mirror abziehen. Oder der Chunk ist ein Hotspot Chunk (100+ References), dann gibt es eine Sicherheitskopie. Wenn keins von beiden zutrifft, wird der defekte Chunk auf die Rote Liste gesetzt, und der Dedupe Prozess achtet bei kommenden Jobs darauf, ob dieser Chunk evtl. frisch hereingekommen ist. Und wird diesen dann gegen den Korrupten austauschen.
under the Hood; Data Optimization
Die Herausforderung der Optimierung besteht darin, Platz zu sparen. Genauer gesagt, mehr Daten in weniger Platz zu speichern, indem die Data Streams der Files auf Blockbasis in variable (32KB bis 128KB) Chunks geteilt werden, und diese in komprimierter Form von mehreren Files referenziert werden. Der Durchschnitts- Chunk liegt normalerweise im oberen Bereich bei 70 – 90 KB pro Chunk. Dateien, die kleiner 32Kb sind, werden von der Optimierung ausgenommen, werden also nicht dedupliziert.
Sehr oft liest man, das bei der Deduplication, wenn ein Replikat entdeckt wurde, dieses gelöscht wird und dafür ein Pointer auf ein bereits vorhandene File gesetzt wird. Die erste Frage hierzu muss dann lauten: was passiert wenn das ursprungs File gelöscht wird? Sind dann beide weg?
Der Prozess wartet nicht auf zwei gleiche Files. Sobald ein File der Policy entspricht, und grösser 32KB ist, wird der Daten Stream, der nur diesem File gehört, entfernt. Die Chunks des Stream werden in den Chunk Store verschoben, und dem File werden Pointer, sogennante Reparse Points angehängt. Diese Pointer verweisen auf die im File jetzt fehlenden Chunks im Chunk Store.
Damit doppelte Chunks identifiziert werden können, wird für jeden Chunk ein Hashwert generiert und abgelegt. Wenn der optimization Prozess einen Chunk in den Chunk Store schieben möchte, der bereits vorhanden ist, wird im vorher auffallen, das es den Hashwert bereits gibt, und wird den Reparse Point des neuen Files auf den bereits vorhanden Chunk verlinken.
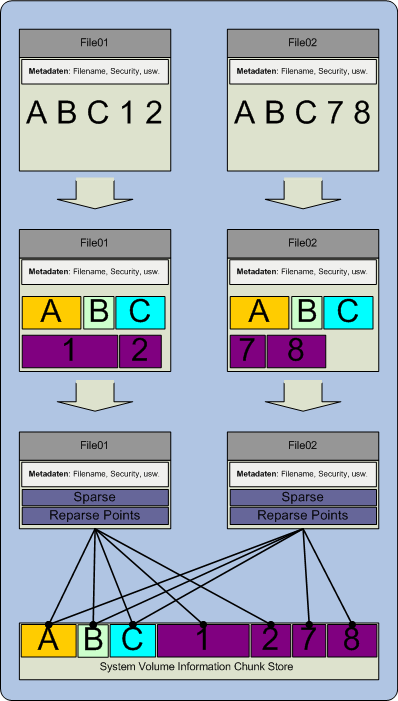
Wenn ein Client ein File anfordert, wird sich der Server 2012 bzw. R2 darum kümmern. Die Daten werden vom Server zusammengesetzt und dem User bzw. der Applikation so übergeben, dass diese keinerlei Kenntnis darüber benötigen, was im Hintergrund geschieht.
Metadaten
sobald ein File optimiert wurde, liegen die Chunks nicht mehr beim File oder Ordner. In den Eigenschaften gibt der Explorer die korrekte logische Grösse der Daten wieder, aber die Grösse die die Daten aktiv belegen, wird mit 0 Bytes angegeben.
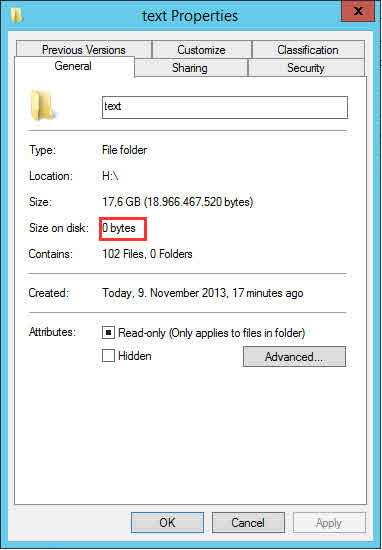
mit folgendem Powershell Befehl lässt sich die tatsächliche Grösse des Ordners berechnen:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
PS C:\Users\administrator.PLAYGROUND> Measure-DedupFileMetadata h:\text
Path : {h:\text}
Volume : H:
VolumeId : \\?\Volume{63bde5fa-01c9-4834-9061-69b19d3856ea}
FilesCount : 102
OptimizedFilesCount : 102
Size : 17.66 GB
SizeOnDisk : 408 KB
DedupSize : 30 B
DedupChunkCount : 2
DedupDistinctSize : 0 B
DedupDistinctChunkCount : 0
|
Von den 102 Files im Ordner Text sind alle 102 optimiert, und haben zusammen eine tatsächliche Grösse von 408KB. Somit belegt jedes optimierte File exakt 4KB Festplattenspeicher (bei default 4096 Bytes/Cluster) für Metadaten und alle notwendigen Reparse Points.
Failover Cluster
wie weiter oben erwähnt liegen die scheduled tasks nicht im Ordner Deduplication sondern in Failover Clustering. Das hat den Hintergrund, beim Schwenken der Disk in einem Cluster, die Tasks mitzunehmen. Die Dedupe Config liegt auf der Partition selbst, die scheduled tasks sind jedoch systemweit. Die Tasks werden über das Quorum übermittelt, das eine Copy des Registry Keys HKLM\Cluster, bzw. HKLM\0.Cluster am aktiven Node beinhaltet.
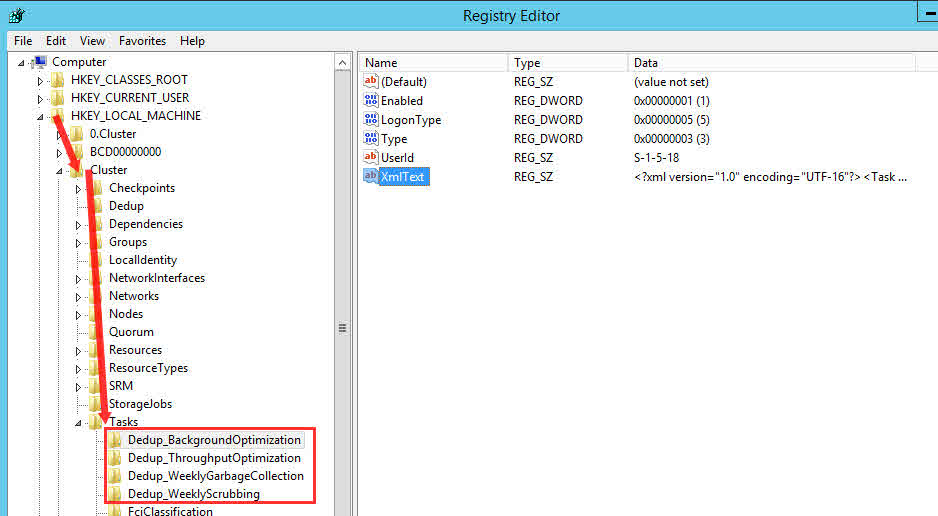
Nach dem schwenken der Disk hat der aktive Node nur Zugriff auf deduplizierte Daten, wenn das Dedupe Feature sprich der Dedupe Filter Driver installiert ist.